 夜雨聆风
夜雨聆风





AI大模型的"中文税":为什么同一条消息,中文比英文贵 64%?
你的每一句中文字,都在替 tokenizer 的历史债务买单
Opus 4.7 刚发布那几天,X 上怨声载道。有人说一次对话就把她的 session 额度用光了,有人说同一段代码跑完的成本比上周翻了一倍多。
Anthropic 官方价格没变,每百万输入 token 仍是 5 美元,输出 25 美元。但这个版本引入了新 tokenizer,加上 Claude Code 把默认 effort 从 high 提到了 xhigh。两件事叠加,同一份工作消耗的 token 变成了以前的 2 到 2.7 倍。
但有意思的是,有人说中文在新 tokenizer 下几乎没涨,中文用户似乎躲过了这一劫。有人甚至说:古文比现代汉语还省 token,用文言文跟 AI 对话可以省钱。
这暗示 Claude 对中文做了某种优化,但 Anthropic 的发布文档里没提过任何和中文相关的调整。另外离奇的是,古文对人类读者显然比现代汉语难懂,一个对人类更复杂的文本,怎么会对 AI 更容易?
于是我跑了 22 段平行文本(商业新闻、技术文档、古文、日常对话),同时送进 5 个 tokenizer(Claude 4.6 和 4.7、GPT-4o、Qwen 3.6、DeepSeek-V3),做了次横向对比。
结论比传言复杂得多。
先看硬数据。
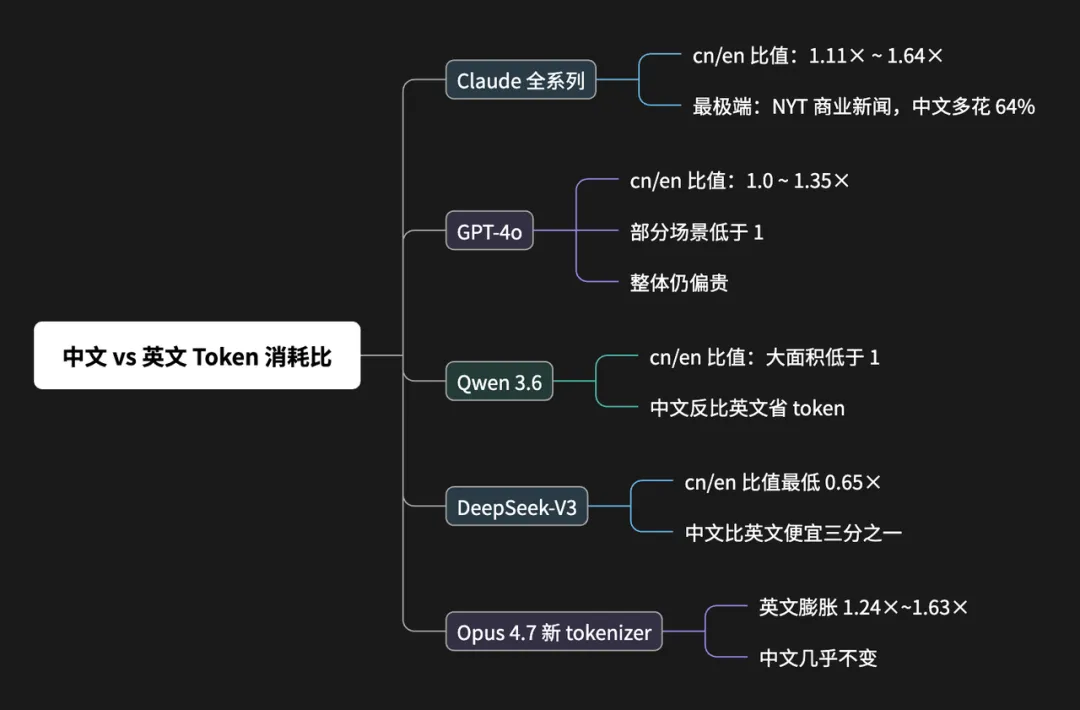
在 Claude 和 GPT 上,中文一直比英文贵。在国产模型 Qwen 和 DeepSeek 上,中文反而比英文便宜。
Opus 4.7 这次引发震荡的 tokenizer 升级,通胀几乎只发生在英文上。开头那些英文开发者的账单震荡,中文用户确实没感受到。
💡 原因可能是中文在旧版上已经被切到了单字颗粒度,可拆分空间极小。
但这不只是账单问题。token 消耗的差异直接影响上下文窗口的有效大小。同样 200k 上下文窗口,用旧版 Claude tokenizer 装中文资料,能塞进去的内容量比英文少 40% 到 70%。
结果就是:付了更多的钱,但得到的是更小的工作空间。
02 | 积木切割机:藏在 tokenizer 里的秘密
为什么同一段内容换个语言,token 数就不一样?为什么 Claude 和 GPT 的中文贵,Qwen 和 DeepSeek 的中文反而便宜?
答案藏在 tokenizer 上。
你可以把 tokenizer 想象成 AI 的「积木切割机」。你输入一句话,它负责把这句话拆成一块块标准化的积木(也就是 token)。AI 模型不看文字,只认积木的编号。你用多少块积木,就付多少钱。

英文的切法比较符合直觉——”intelligence”大概率是一个 token,”information”也是一个 token,一个单词对应一个计费单位。
但中文到了这一步就出问题了。
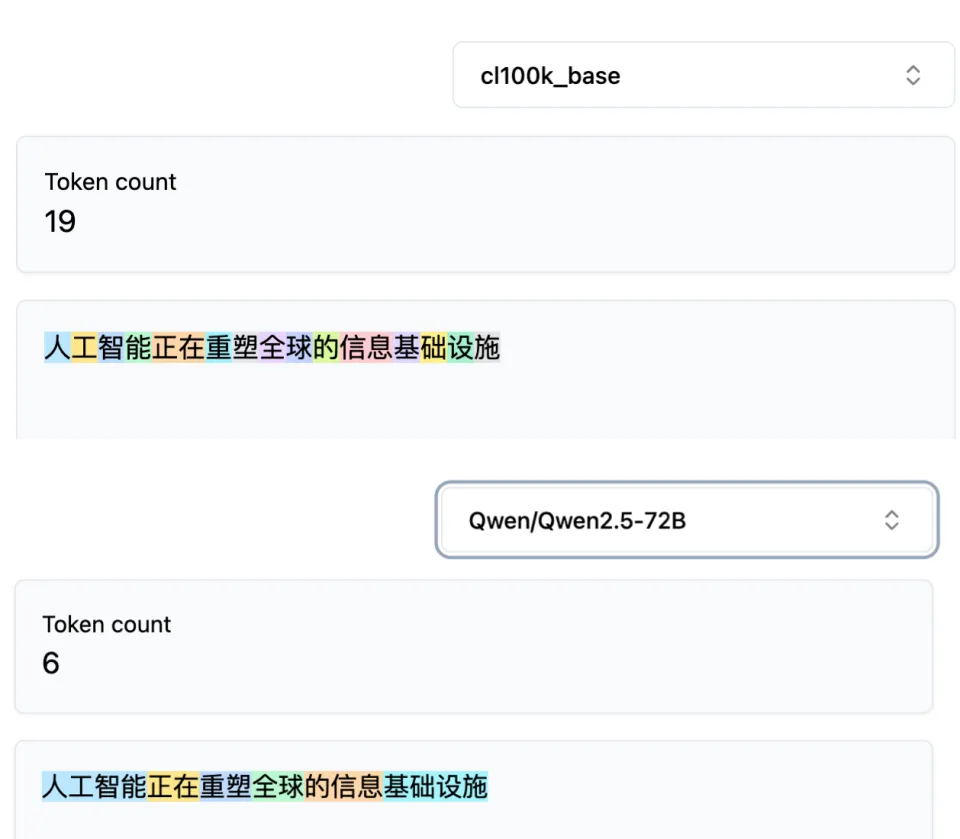
同一句 16 个汉字的话,GPT-4 切出来 19 个 token,Qwen 切出来只有 6 个。
为什么会切成这样?原因在一个叫 BPE(Byte Pair Encoding) 的算法。
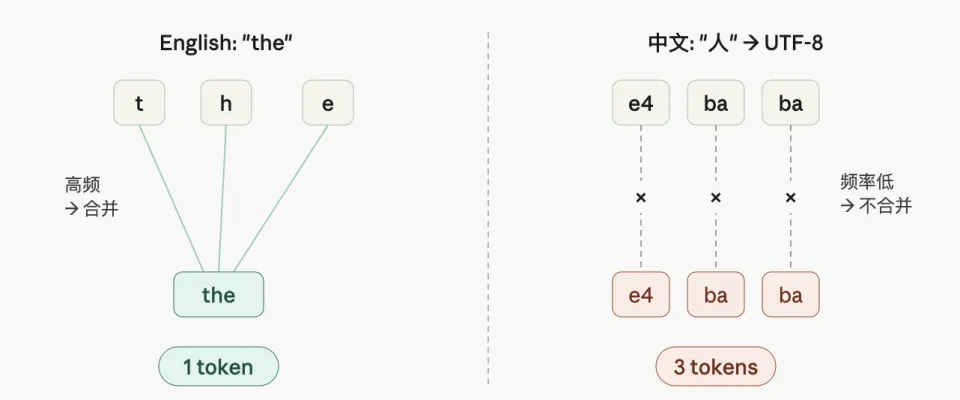
BPE 的工作方式,是统计训练语料里哪些字符组合出现频率最高,然后把高频组合合并成一个 token,纳入词表。
GPT-2 时代,训练语料的绝大多数是英文。英文字母组合(th、ing、tion)反复出现,很快就被合并成 token。中文字符在那个语料池里出现的频率太低,排不进词表,只能被当作原始字节来处理,一个字占 3 个字节,就变成了 3 个 token。
后来 GPT-4 的 cl100k 词表扩大了,常用汉字开始被纳入,一个字通常缩到 1 到 2 个 token,但整体效率仍然不如英文。到了 GPT-4o 的 o200k 词表,中文效率再进了一步。

而 Qwen 和 DeepSeek 作为国产模型,从一开始就把大量常用汉字和高频词组作为整字、整词纳入词表。一字一 token,效率直接翻倍甚至更多。
🎯 核心洞察:Claude 和早期 GPT 的词表以英文为默认值构建,中文是后来被”塞进去”的;Qwen 和 DeepSeek 的词表从设计之初就把中文当作默认语言对待。
这个起点的差异,一路传导到 token 数、账单、上下文窗口大小。
03 | 碎片里长出偏旁:一个意外的语义通道
2025 年发表的一篇论文(《Tokenization Changes Meaning in Large Language Models: Evidence from Chinese》),发现了一个惊人的巧合。
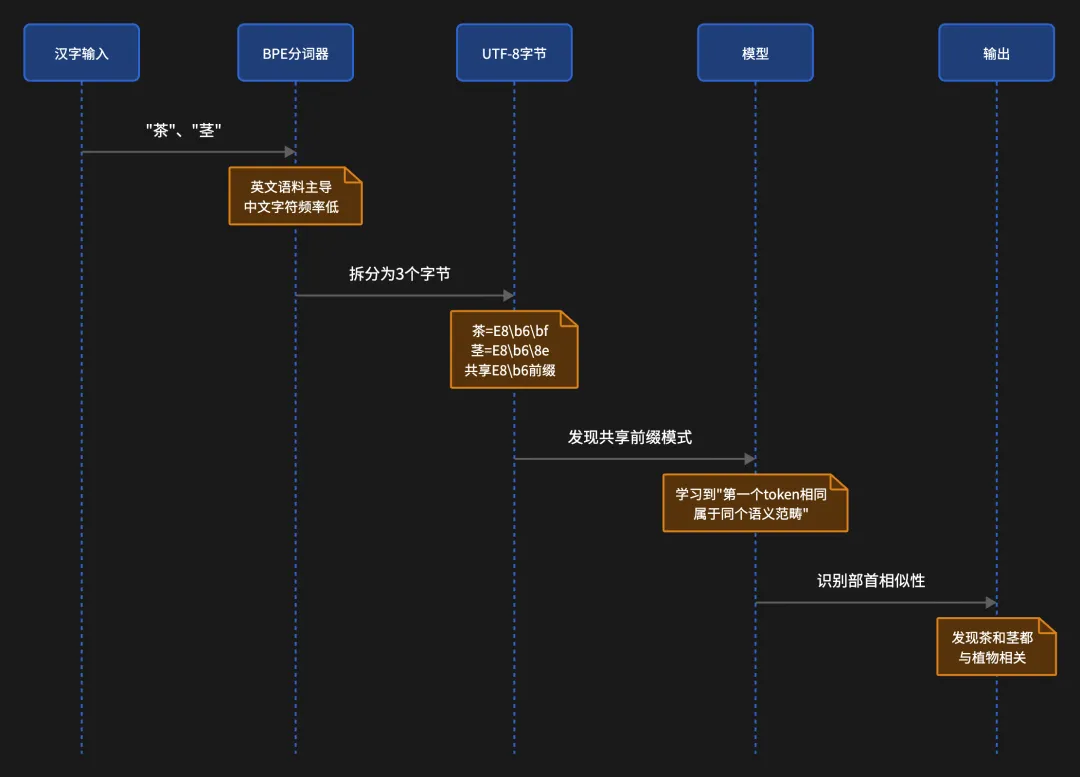
1990 年代,Unicode 联盟在给汉字分配 UTF-8 编码时,排列顺序是按部首归类排的。同一个部首下的汉字,UTF-8 编码是相邻的。”茶”和”茎”都含有”艹”部(草字头),它们的 UTF-8 字节序列以相同的字节开头。”河”和”海”都含有”氵”部,字节序列同样共享开头。
这意味着,当 tokenizer 把汉字拆成三个 UTF-8 字节 token 的时候,共享部首的汉字会共享第一个 token。模型在训练过程中反复看到这些共享的字节模式,有可能从中学到”第一个 token 相同的字,往往属于同一个意义范畴”。这在功能上就接近于人类通过偏旁判断语义的过程。
论文设计了三个实验来验证这件事:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
三个实验的结论一致:当汉字被切成多个 token 时(如 GPT-4 的旧 tokenizer 下,89% 的汉字被切成了多 token),模型识别共享部首的准确率更高;当汉字被编码为单个 token 时(GPT-4o 的新 tokenizer 下,只有 57% 的汉字还是多 token),准确率下降了。
把汉字切碎,成本确实更高,但切碎后的字节序列里保留了部首的痕迹,模型真的从中学到了一些东西。而把汉字编码为整字 token,成本降下来了,但部首信息被封装在一个不透明的编号里,模型无法再通过字节序列获取这一线索。
🎁 需要说明的是,这一结论仅局限于字形相关的细分语义任务,不能等同于模型整体的中文理解、逻辑推理能力下降。主流共识依然是针对目标语言优化的整词/整字分词器能显著提升模型整体性能。
但这件事戳中了大型系统里最难处理的一类问题:你能优化你设计过的部分,但你没法优化你不知道自己拥有的部分。
Unicode 联盟按部首排列编码,是为了人类检索的方便。BPE 把汉字拆成字节,是因为中文在语料里的频率太低。两个不相关的工程决策碰巧叠在一起,产生了一条谁都没规划过的语义通道。
然后,当新一代工程师”改进” tokenizer、把汉字合并为整字 token 的时候,他们同时抹掉了一条自己不知道存在的路。
04 | 林语堂:一个跨越 80 年的对照实验
中文适配西方技术基础设施的代价,不是 AI 时代才开始付的。
2025 年 1 月,纽约居民 Nelson Felix 在 Facebook 打字机爱好者小组里发了几张照片。他在妻子祖父的遗物里发现了一台刻满中文的打字机,不知道是什么来历。

斯坦福大学汉学家墨磊宁(Thomas S. Mullaney)看到照片后立刻认出来了——这是林语堂 1947 年发明的「明快打字机」的唯一原型机,失踪了将近 80 年。
明快打字机要解决的问题,和今天 tokenizer 面对的问题在结构上是同一个:怎么把中文高效地嵌入一套为西方语言设计的技术基础设施。
1940 年代的英文打字机有 26 个字母键,一键一字,简单直接。中文有几千个常用字,不可能一键一字。当时的中文打字机是一个巨大的字盘,排着几千个铅字,打字员用手逐个捡字,每分钟只能打十几个字。

林语堂耗资 12 万美元研发经费,几乎倾家荡产,做出了一台只有 72 个键的中文打字机。
工作原理是把汉字按字形结构拆开,上形键选字根上半部、下形键选字根下半部,候选字显示在一个叫”魔术眼”的小窗里,按数字键选中。每分钟 40 到 50 字,支持 8000 余常用字符。

💡 墨磊宁在《中文打字机》里有一个判断:明快打字机作为一款 1940 年代的产品确实失败了,但作为一种人机交互范式,它胜利了。林语堂第一次把中文”打字”变成了”检索加选择”。这正是所有现代中文输入法的底层逻辑。
从仓颉、五笔到搜狗拼音,都可以说是明快打字机的后裔。
这台打字机和 tokenizer,在结构上是同一个问题的两个版本。 中文始终面对着一个问题:如何接入一套罗马字母形成的基础设施。
有趣的是,在这个寻找的过程中,充满了非人为规划的巧合。Unicode 联盟为了人类检索方便制定的排序,跟 BPE 算法的无心拆解叠在一起,竟然在神经网络的黑盒里,重现了人类识字的过程。而当工程师们为了消除”中文税”,主动把汉字拼好、把成本打下来时,那条意外诞生的语义通道也闭合了。
05 | 底层逻辑:每一套基础设施都有自己的默认值
回到一开始的问题。
“中文在 AI 里多付钱”这个判断没错,但事情比它复杂得多。
每一种 tokenizer 都在为某个默认值优化,代价藏在了别处。
Claude 和 GPT 的 tokenizer 以英文为默认值——英文用户付出了更少的 token 成本,但失去了通过字节序列获取汉字部首信息的语义通道。Qwen 和 DeepSeek 的 tokenizer 以中文为默认值——中文用户的 token 成本大幅降低,但同样失去了那条通道。
没有完美的默认值。任何对某种语言的”优化”,都包含了对其他某种信息的”舍弃”。
这条规律可以延伸到更远的地方。从打字机到键盘,从编码标准到 tokenizer,历史并不是一条直线进化的轨道,而是在各种约束条件的挤压下,不断发生变形的流体。
有些能力是设计出来的,有些只是碰巧没有被删掉。
📌 当我们在谈论”中文税”的时候,我们实际上在问一个更深的问题:谁的语言是默认值,谁的语言需要额外付费才能获得同等待遇?
这个问题的答案,从 1947 年的打字机到 2025 年的 tokenizer,一直没有变过。
🦞AI技术交流群

-
• 💻 GitHub 账号 @NimaChu – 获取开源代码和产品更新 -
• 👀 关注微信公众号:[NimaTech] – 获取最新技术文章和产品动态
🙌 看完点个赞,Agent不摆烂🦞