 夜雨聆风
夜雨聆风





AI大模型+数据仓库:如何用AI重构DWD层?3个落地场景彻底讲透,附案例

加v:cqhg_bigdata,备注2026AI,送你一份清华大学《2026大模型工具大全》一次看遍各个领域的AI利器.pdf

前言:DWD层为什么成了瓶颈
DWD层的核心工作是“理解数据”——字段含义是什么、业务规则怎么定、异常值如何处理、多源数据怎么对齐。这些工作过去依赖数据工程师逐字段阅读文档、逐表编写ETL逻辑。当企业数据源从几十个膨胀到几百个,表的数量从几百张变成几万张时,人工理解的速度已经远远跟不上业务需求的变化速度。
而大模型的能力恰好切中了这个痛点:理解语义、识别模式、生成代码。
场景一:自动化的数据探查与语义标注
传统方式的困境
数据团队接到新需求的第一步永远是“摸表”。面对一张从业务系统同步过来的ODS表,字段名通常是拼音缩写或开发人员随意命名的英文单词。比如一张订单表里可能出现这样的字段:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
传统方式下,数据工程师需要:
-
翻阅业务系统文档(如果存在的话) -
找开发人员询问字段含义 -
通过SQL采样分析值分布来反推业务规则 -
手工编写字段注释和清洗规则文档
这个过程对于一张100个字段的表,熟练的工程师也需要2-4小时才能完成初步探查。当ODS层有3000张表时,完整梳理一轮的工作量是惊人的。
AI重构后的流程
大模型介入后,整个探查流程发生了结构性变化。以下是新的工作流:
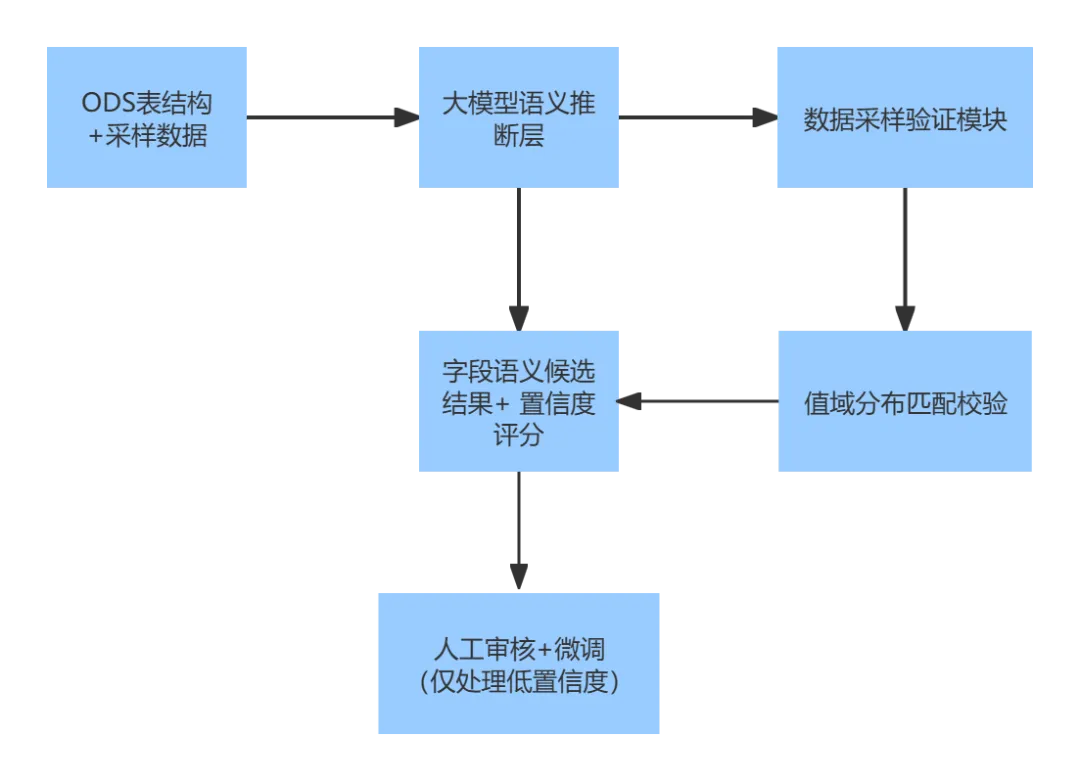
技术实现细节
核心思路是利用大模型的few-shot learning能力,配合结构化的Prompt工程。以下是一个经过生产验证的Prompt框架:
-- Prompt输入示例## 任务:根据以下ODS表结构和采样数据,推断每个字段的业务含义、数据类型、清洗规则## 表名:ods_order_info_v2## 数据源:零售业务-订单系统## 字段列表及采样数据:- field_01: 字段名=ord_no, 采样值=['ORD20250101001','ORD20250101002','ORD20250101003']- field_02: 字段名=ord_st, 采样值=[1,2,1,3,1,4,5,1], 去重计数=5- field_03: 字段名=amt, 采样值=[199.00, 458.00, 1299.00, 89.90], 数据类型=decimal(10,2)- field_04: 字段名=ext_j, 采样值=['{"src":"APP","v":"2.1"}','{"src":"MINI","v":"2.0"}']...## 输出要求:对每个字段输出1. 业务含义(中文)2. 建议的DWD字段命名3. 数据类型(建议标准化为string/bigint/decimal/datetime)4. 清洗规则(如空值处理、异常值处理、枚举标准化)5. 置信度(0-1)实际运行中,GPT-4或Claude-3.5对上述任务的处理效果如下:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
真实体验与反思
在电商零售企业的实际落地中,这套方案处理了约800张ODS表,字段总数约1.2万个。统计数据显示:
-
高置信度字段(>0.9)占比约47%:可直接采纳,无需人工复核 -
中置信度字段(0.7-0.9)占比约35%:需要人工快速确认,但已有候选答案 -
低置信度字段(<0.7)占比约18%:通常是业务特有命名或拼音缩写,需要人工深度介入
整体效率提升约3-4倍——原来需要5人日完成的探查工作,现在1人日可以完成。
但有几个值得注意的问题:
-
枚举值的边界:模型能推断出“状态字段”,但具体的枚举映射关系仍然需要查文档或代码。解决方案是让模型标记出“需要确认枚举映射”的字段,再由人工补充。
-
跨表关联推断的局限:单表推断效果不错,但多表之间的外键关系推断准确率只有60%左右,这部分目前仍需依赖元数据管理系统。
-
增量更新的增量价值:首次全量探查的价值最大,后续增量表的结构变化探查边际成本很低,这也是AI方案相比纯人工的显著优势。
场景二:智能SQL生成与复杂清洗逻辑构建
传统方式的困境
DWD层的ETL开发中,大量时间消耗在编写重复性极高的清洗SQL上。虽然现在有dbt这样的工具提升了代码复用性,但核心逻辑的编写仍然是手工作业。
典型的一类问题是“多源同义字段的标准化”。例如,来自不同业务线的三张订单表:
表A(自营电商): order_status = 'PAID', 'SHIPPED', 'DONE'表B(第三方平台): status = 20, 30, 40 -- 20=已付款,30=已发货,40=已完成表C(线下门店): state = '待支付', '待发货', '待收货'数据工程师需要阅读三份文档,理解三套编码体系,然后手写CASE WHEN或JOIN映射表来统一成DWD层的标准枚举。
AI重构后的流程
大模型在这个场景下能够直接理解枚举映射关系,并生成符合规范的清洗SQL。工作流程如下:
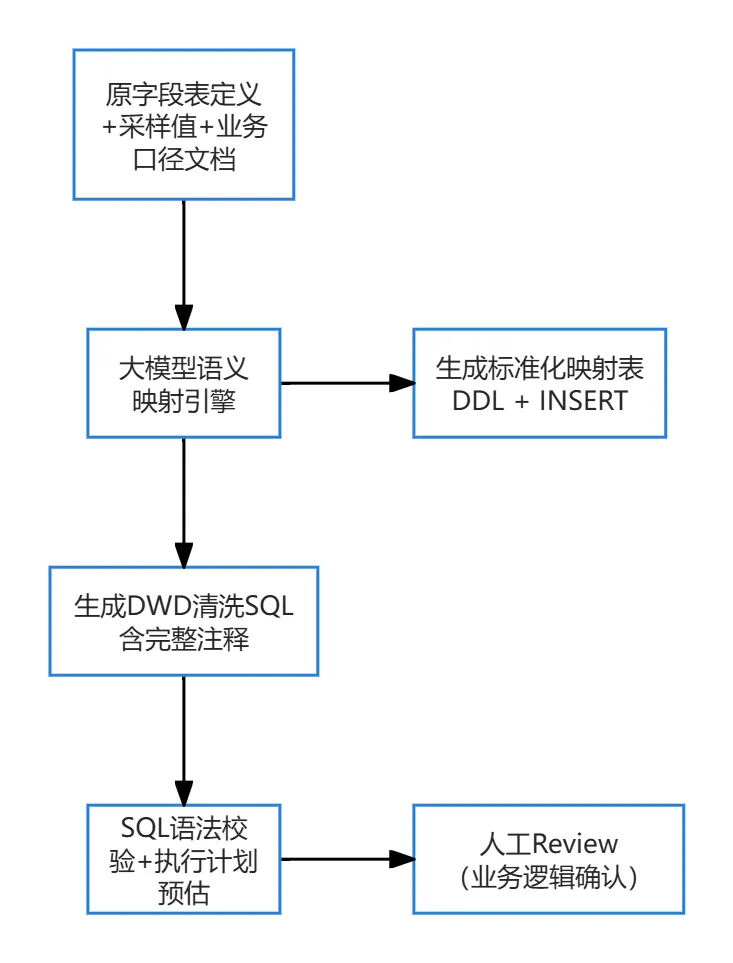
技术实现:结构化Prompt + 知识库RAG
这个场景下单纯靠大模型“理解”是不够的,需要配合企业知识库做检索增强生成(RAG)。架构如下:
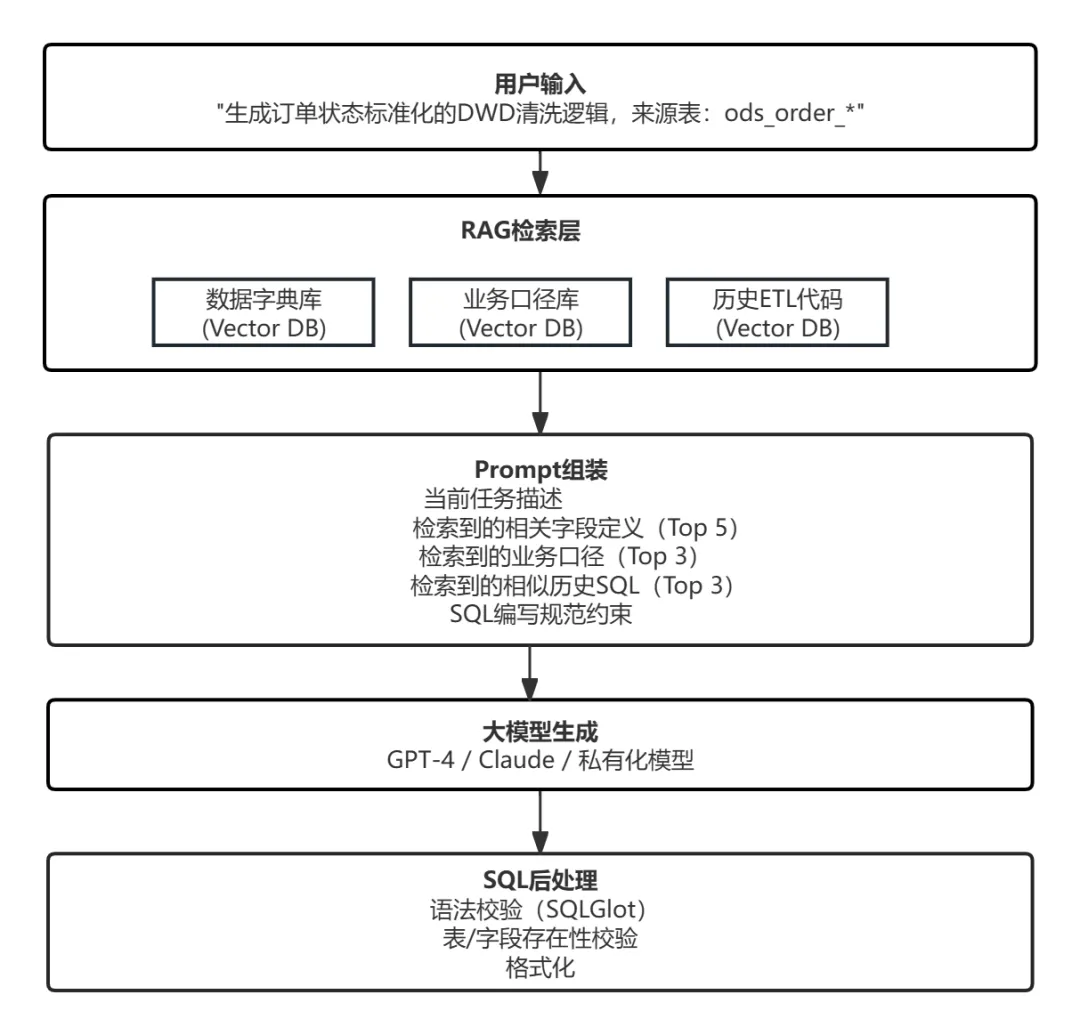
生成效果示例
生成的DWD清洗SQL(脱敏后):
-- ============================================================-- DWD层:订单明细宽表 ETL-- 表名:dwd_order_detail_df-- 生成方式:AI辅助生成 + 人工确认-- 生成时间:2026-04-11-- ============================================================WITH order_base AS (-- 多源订单数据合并,统一状态映射SELECT order_id, order_source,-- 使用映射表统一订单状态COALESCE(m.status_std, 'UNKNOWN') AS order_status_std,-- 原始状态保留用于回溯 a.order_status_raw, a.payment_amount, FROM_UNIXTIME(a.create_time) AS create_time_stdFROM (SELECT order_id,'A'AS order_source, order_status AS order_status_raw,CAST(REPLACE(order_amount, ',', '') ASDECIMAL(12,2)) AS payment_amount, create_timestamp AS create_timeFROM ods_order_source_aWHERE dt = '${bizdate}'UNIONALLSELECT order_id,'B'AS order_source,CAST(status_code ASSTRING) AS order_status_raw, total_fee / 100.0AS payment_amount, -- 分转元 created_at AS create_timeFROM ods_order_source_bWHERE dt = '${bizdate}' ) aLEFTJOIN dim_order_status_mapping m ON a.order_source = m.source_system AND a.order_status_raw = m.source_status_code)-- 后续JOIN逻辑...真实体验与反思
在某金融科技公司落地时,这套方案覆盖了约60%的DWD层日常ETL开发需求。统计数据显示:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
但实践中也暴露出几个关键问题:
-
复杂嵌套逻辑的边界:当清洗逻辑涉及3层以上的子查询嵌套,且包含多个LEFT JOIN时,模型生成的SQL有时会出现字段引用错误。当前解决方案是引导模型采用CTE风格编写,分段生成、分段验证。
-
历史代码的“污染”问题:RAG检索历史ETL代码时,如果历史代码本身质量不高(比如硬编码了已过期的业务规则),模型可能会“学习”到错误模式。需要建立代码质量评分机制,只检索高质量样本。
-
方言适配成本:不同数据仓库(Hive、Spark SQL、ClickHouse、Snowflake)的SQL方言差异较大,需要针对性做Prompt约束或后处理转换。
具体建议
-
建立ETL代码知识库:将经过Code Review的高质量DWD层ETL代码入库,作为RAG的核心语料 -
维护业务术语词典:字段映射、状态码映射等元数据统一管理,作为Prompt的上下文注入 -
采用分段生成策略:复杂清洗逻辑拆解为多个步骤,每个步骤独立生成、独立验证
场景三:数据质量监控规则的自动生成
传统方式的困境
DWD层上线后,数据质量监控是保障下游应用可靠性的关键。传统做法是数据工程师根据经验编写质量规则:
-
主键唯一性检查 -
非空字段的空值率监控 -
枚举字段的值域合规性检查 -
金额字段的非负检查
问题在于,规则编写完全依赖人的经验和责任心。工程师容易遗漏检查项,尤其是在面对不熟悉的业务域时。
AI重构后的流程
大模型能够根据字段语义和数据分布特征,自动推断合理的质量监控规则。核心思路是“统计特征 + 语义理解 = 规则推荐”。
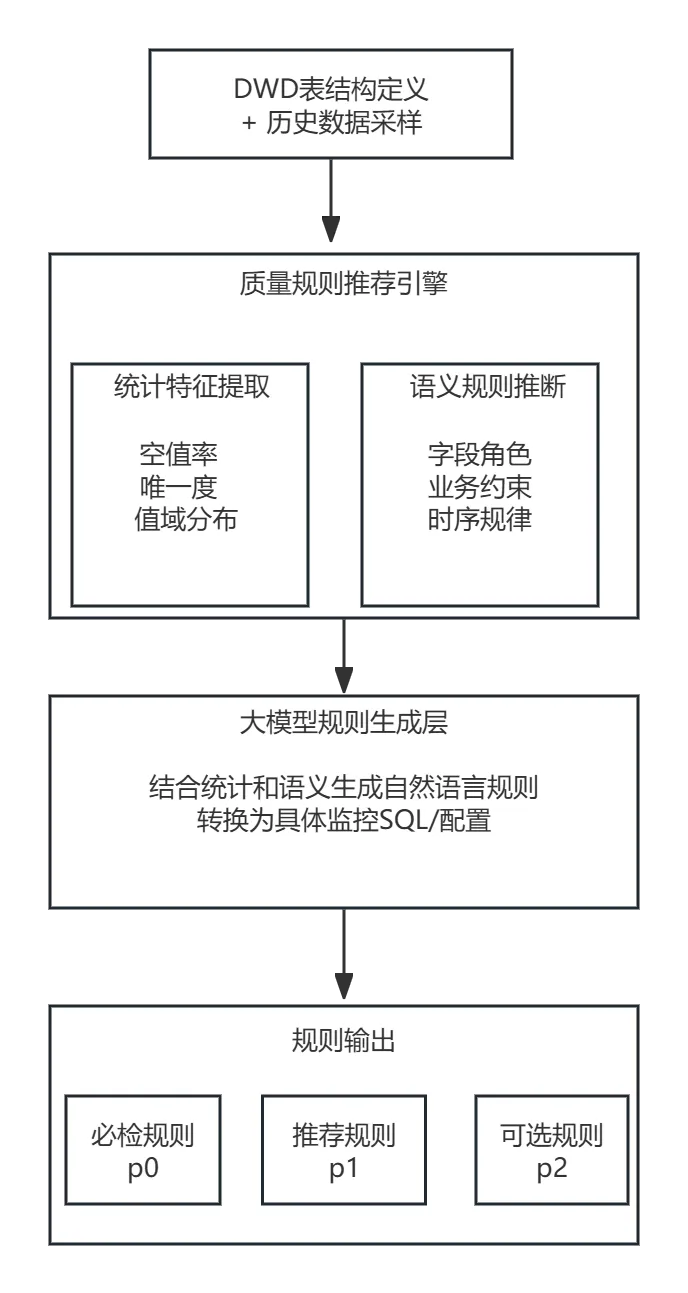
生成效果示例
针对DWD层的订单表,模型自动生成的监控规则如下:
表名:dwd_order_detail_df规则集版本:v1.0_auto_generated生成时间:2026-04-11必检规则_P0:-规则ID:DQ001描述:主键order_id唯一性检查类型:唯一性SQL:SELECT COUNT(*)-COUNT(DISTINCT order_id) AS dup_cnt FROM ${table}阈值:dup_cnt=0-规则ID:DQ002描述:订单创建时间非空检查类型:非空SQL:SELECT COUNT(*) AS null_cnt FROM$ {table} WHERE create_time IS NULL阈值:null_cnt=0-规则ID:DQ003描述:订单金额合理性检查(非负且小于上限)类型:值域SQL:SELECT COUNT(*) AS abnormal_cnt FROM ${table}WHERE payment_amount <0 OR payment_amount>1000000阈值:abnormal_cnt=0推荐规则_P1:-规则ID:DQ004描述:订单状态枚举合规性检查类型:枚举SQL:SELECT COUNT(*) AS invalid_cnt FROM ${table}WHERE order_status_std NOT IN('待支付','已支付','已发货','已完成','已取消','退款中','已退款')阈值:invalid_cnt=0-规则ID:DQ005描述:创建时间时序合理性检查(不应晚于当前时间)类型:时序SQL:SELECT COUNT(*) AS future_cnt FROM ${table}WHERE create_time>CURRENT_TIMESTAMP阈值:future_cnt=0可选规则_P2:-规则ID:DQ006描述:订单金额与商品明细金额的一致性校验类型:跨表一致性说明:需关联dwd_order_item_df表进行汇总比对SQL:[复杂SQL略]建议:每日T+1执行真实体验与反思
在零售企业的数据质量平台中落地后,效果显著:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
关键发现:
-
P0规则几乎可以直接采纳:主键唯一性、核心字段非空这类规则,模型推荐准确率接近100%。
-
跨表一致性规则需要人工校准:模型能识别“订单金额应该等于商品明细汇总”,但具体的关联条件和聚合粒度,需要人工确认。建议将这类规则标记为“建议审查”。
-
业务周期特征的学习:对于存在明显周期性波动的指标(如每日订单量),模型可以从历史数据中学到波动范围,自动设置动态阈值。这项能力在传统手工配置中几乎不可能实现。
文末可加入社群下载资料
整体架构建议
将上述三个场景整合起来,形成AI增强型DWD层开发全流程:
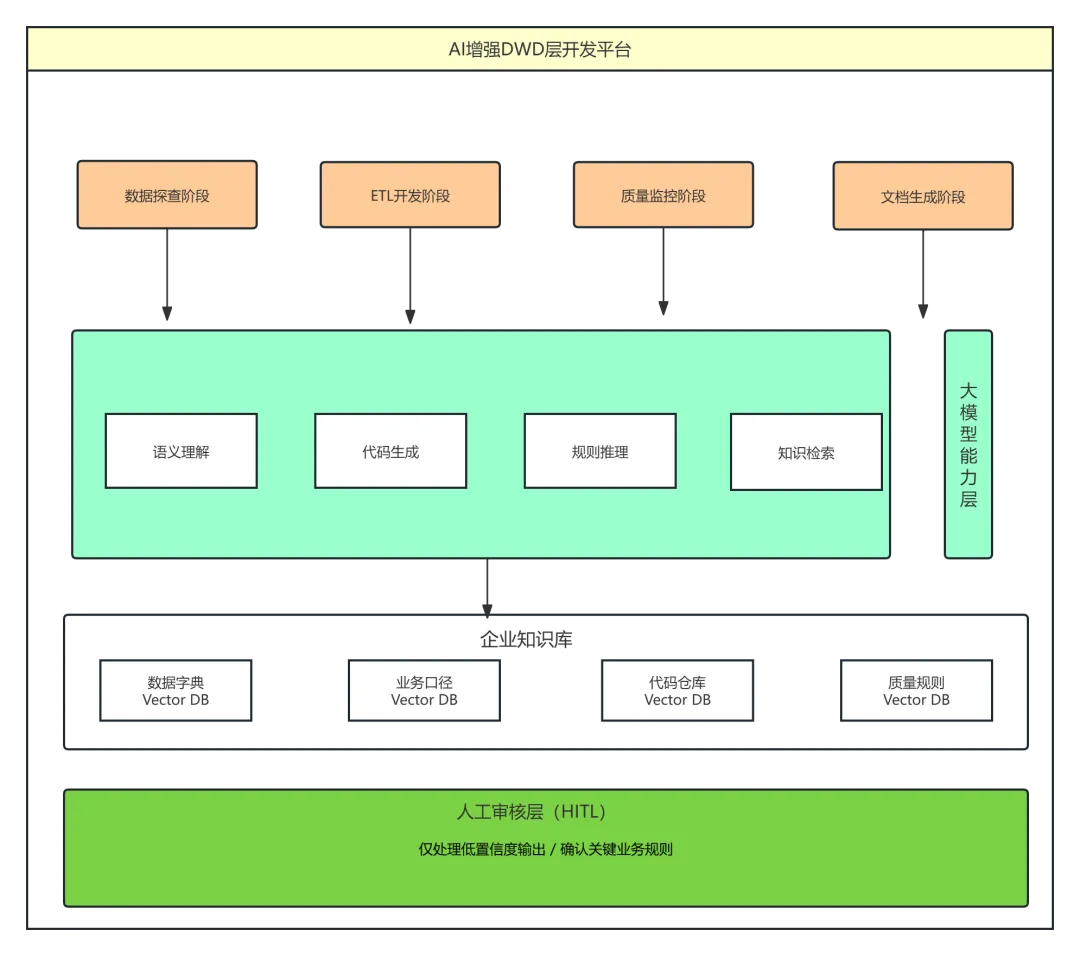
落地路线图与优先级建议
基于多个项目的实际落地经验,以下是分阶段推进建议:
第一阶段(1-2个月):单点突破,验证价值
目标:选择一个痛点最明显的场景快速验证
推荐起点:场景一(自动化数据探查与语义标注)
-
理由:输入输出明确,不涉及复杂代码执行,风险可控 -
产出:字段语义标注结果、数据探查报告 -
衡量指标:探查效率提升倍数、人工确认比例
技术栈选型:
-
大模型API:Claude-3.5-Sonnet或GPT-4(处理长上下文效果好) -
向量数据库:Milvus或Pinecone(存储字段定义和历史标注) -
工作流编排:自研Python脚本即可,暂时不需要复杂框架
第二阶段(2-3个月):扩展深度,串联流程
目标:覆盖ETL开发和简单质量规则生成
关键工作:
-
建立企业知识库(数据字典、业务口径、高质量ETL代码) -
开发Prompt管理模块(版本控制、A/B测试) -
接入SQL语法校验和权限控制
第三阶段(3-6个月):平台化,规模化
目标:建设AI增强型DWD开发平台,覆盖全流程
关键工作:
-
开发可视化操作界面 -
建立模型输出评估体系(准确率、采纳率、人工修正成本) -
形成标准化SOP
风险与边界:AI不是银弹
1. 大模型擅长的是“加速”而非“替代”
DWD层的核心业务逻辑判断,最终仍然需要人来确认。AI的价值在于把“从0到1写草稿”的时间压缩到分钟级,让人把精力集中在“判断和优化”上。
2. 私有化部署vs公有云API的权衡
涉及核心业务数据时,数据安全是首要考量。目前可行方案:
-
敏感数据脱敏后调用公有云API(适用于探查阶段) -
私有化部署开源模型(Llama-3-70B等)处理核心ETL逻辑生成 -
混合架构:非敏感场景用API,敏感场景走私有化
3. 模型能力的“长尾效应”
对于80%的标准场景,AI表现优秀;剩下20%的复杂场景(如涉及金融合规计算、多层级回溯逻辑),仍需资深数据工程师深度介入。关键在于设计好“AI处理标准场景,人处理异常场景”的分工机制。
4. 持续维护成本不可忽视
Prompt需要随着业务变化持续调优,知识库需要持续更新。这不是一次性项目,而是需要长期运营的能力建设。
结语
大模型重构DWD层这件事,本质上不是在“用AI写SQL”,而是在“用AI理解业务”。当模型能够理解“这个字段表示订单状态,有7种取值,其中’已取消’状态下的订单金额不应该计入GMV”这样的业务语义时,数据开发的范式就真正发生了变化。
三个场景的实践表明,现阶段AI最大的价值点是:
-
消除重复性脑力劳动:字段探查、注释编写、简单SQL生成 -
降低知识门槛:新人可以借助AI快速理解陌生数据域 -
减少遗漏:质量规则的自动推荐填补了人工经验盲区
而需要持续投入的方向是:
-
知识库建设:AI的上限由喂给它的高质量数据决定 -
人机协作流程设计:定义清楚哪些环节AI自主决策,哪些环节必须人工介入 -
评估体系建设:量化AI输出的质量,驱动持续优化

广告人士勿入,切勿轻信私聊,防止被骗

点下方的“❤”支持我们,非常感谢!