夜雨聆风
夜雨聆风





深层次AI应用方法论:从场景选择到创新突破,一套框架打天下

点击上方蓝字关注我们吧

不追逐热点,而是建立可复用的方法论——这才是AI应用研究的“元能力”
医疗影像分割、工业故障诊断、电商推荐系统、教育知识追踪……这些看似毫不相干的AI应用场景,底层其实遵循着同一套方法论逻辑。
本文提出一套通用AI应用实施框架,帮助研究者和工程师:
-
无论面对什么场景,都能快速找到切入点
-
掌握数据处理、模型复现、评价指标的核心要点
-
在成熟Baseline基础上,找到可持续的创新路径
扫一扫,进群一起交流学习⬇️ 
通向顶会顶刊学习交流群
01 第一步:选择具体应用场景
“AI+行业”的空泛表述,是论文被拒的第一大原因。选择场景时,建议遵循以下原则:
场景选择三原则
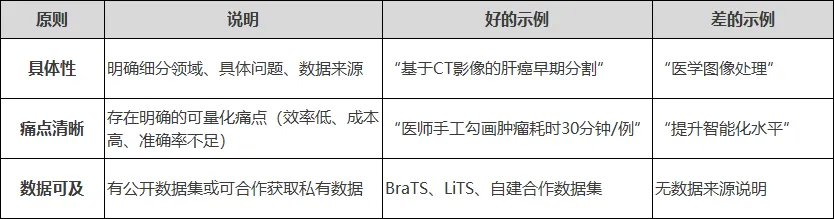
常见应用场景池
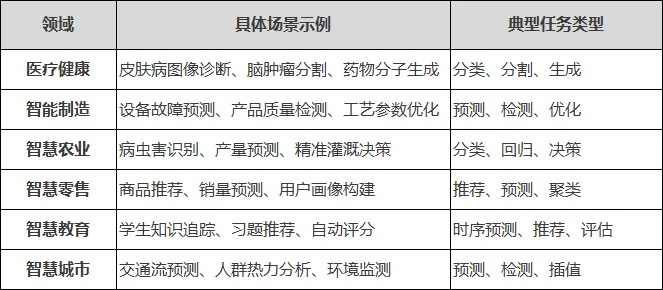
02 第二步:复现成熟Baseline
选择场景后,不要急于“创新”。先复现一个成熟的Baseline模型,建立可对比的基准。
常用Baseline模型池
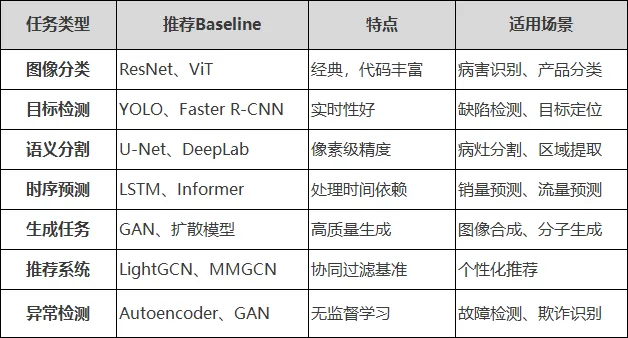
复现核心要点
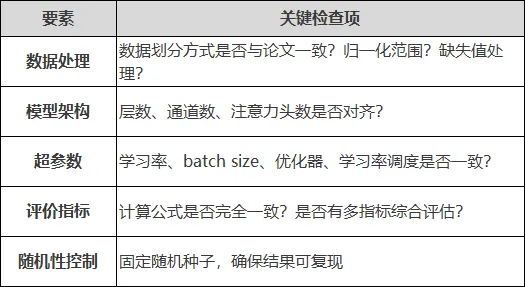
重要原则:在复现指标接近原论文之前,不要开始创新。否则你无法判断指标变化是来自创新还是来自实验设置的偏差。
03 第三步:重点掌握三大核心要素
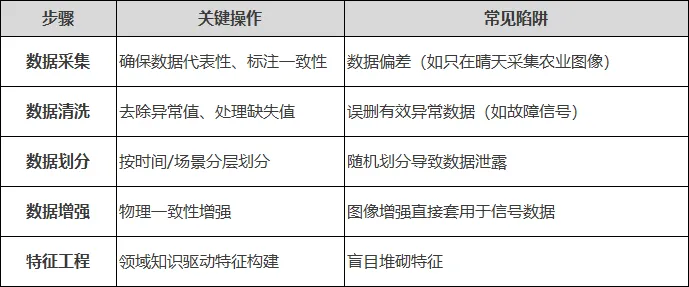
要素一:数据处理流程
数据处理决定了模型的上限。无论什么场景,都需要掌握以下要点:
要素二:生成机制原理
对于生成类任务(如图像生成、文本生成、分子生成),需要深入理解生成机制:
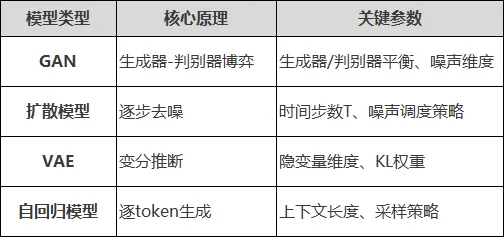
理解要点:
-
生成模型的本质是学习数据分布,而非决策边界
-
训练稳定性和生成多样性之间存在trade-off
-
采样策略直接影响生成质量
要素三:评价指标计算
评价指标必须与任务目标对齐。常见任务的指标选择:
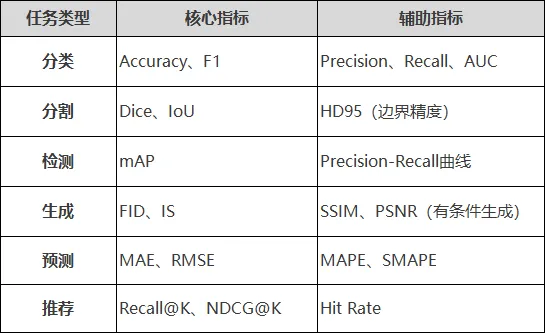
关键原则:
-
单一指标不能全面反映模型性能
-
生成任务需要同时评估“真实性”和“多样性”
-
工业场景需要关注“业务指标”而非仅技术指标
04 创新路径:三个可复用的创新方向
当你完成Baseline复现,理解了核心机制后,以下三个创新方向可以通用到绝大多数AI应用场景:
创新方向一:条件生成控制
核心思路:在生成过程中加入条件约束,使生成结果可控、可定制。
技术方法:
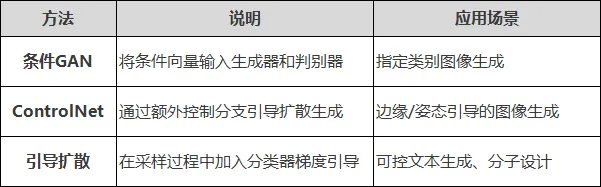
论文切入点示例:
“现有医学图像生成方法缺乏对病灶位置、大小等关键属性的控制能力。本文提出一种条件扩散模型,通过解剖结构引导,实现对生成图像中病灶位置和大小的精准控制,为医学图像数据增强和临床教学提供了新工具。”
创新方向二:多模态融合
核心思路:结合多种数据源(图像、文本、音频、传感器),利用信息互补提升模型性能。
技术方法:
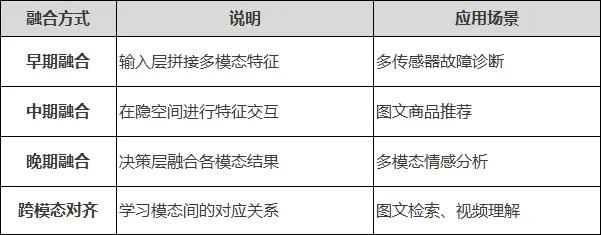
论文切入点示例:
“传统农作物病害检测仅依赖视觉图像,难以区分表观相似的真菌性和细菌性病害。本文提出一种图文多模态融合方法,将病害文本描述与视觉图像联合建模,在病害细粒度分类任务上准确率提升12.3%。”
创新方向三:物理约束嵌入
核心思路:将领域知识(物理规律、化学原理、医学先验)编码进模型,提升泛化能力和可解释性。
技术方法:
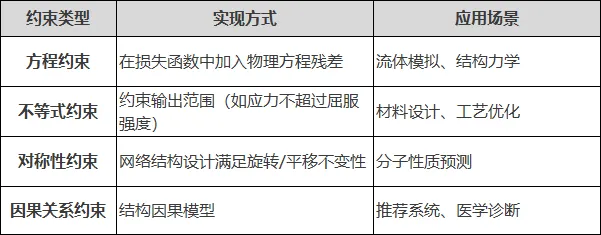
论文切入点示例:
“现有深度学习模型预测机械零件寿命时,常输出违反材料疲劳规律的预测结果。本文提出一种物理约束神经网络,将Miner线性累积损伤理论编码为损失函数的正则项,在保证精度的同时确保预测结果符合物理规律,显著提升了模型的可信度。”
05 实施检查清单
在开展AI应用研究时,可以用以下清单自我检查:
场景定义
-
场景是否足够具体?(作物种类、病害类型、设备型号)
-
痛点是否清晰可量化?
-
数据来源是否明确(公开/自建/合作)?
Baseline复现
-
是否选择了领域内认可的主流模型?
-
复现指标是否接近原论文(误差<1%)?
-
数据处理流程是否完全对齐?
核心机制掌握
-
是否理解模型的输入输出格式?
-
是否掌握损失函数的设计意图?
-
是否知道评价指标的物理含义?
创新设计
-
创新方向是否针对场景具体痛点?
-
是否在Baseline基础上进行对比?
-
是否有消融实验验证每个创新点的贡献?
实验验证
-
是否在公开数据集上验证?(泛化性)
-
是否在自建数据集上验证?(场景适配)
-
是否有案例展示和错误分析?
结语:建立自己的AI应用方法论
AI应用研究的核心能力,不是追逐每一个新热点,而是建立一套可复用的方法论框架。
无论你面对的是医疗影像、工业信号、电商数据还是教育日志,这套框架都能帮你:
-
快速定位具体场景和痛点
-
稳健复现成熟Baseline
-
深入理解数据处理、模型机制、评价指标
-
系统创新——从条件控制、多模态融合、物理约束三个方向找到突破口
当你掌握了这套方法论,你会发现:场景可以千变万化,但解决问题的逻辑始终如一。
希望这篇学习笔记能帮你建立自己的AI应用研究框架。如果你正在某个具体场景中探索,欢迎留言交流讨论。