 夜雨聆风
夜雨聆风





生成式AI与随机微分方程:第六章 构建大规模模型
构建大规模模型
6.1 神经网络架构
当我们从理论走向实践时,一个关键问题浮现出来:我们如何让数学公式真正”活”起来,在计算机中运转?本节我们将探讨如何为流和扩散模型打造一颗强大的”心脏”——可扩展的神经网络架构。
具体而言,我们要解决的核心问题是:如何实现那个带着引导条件的向量场 ?想象一下,这个向量场就像是一位经验丰富的画家,它需要三样东西才能创作:一是当前的状态 (画布上的颜料),二是我们希望它画什么 (文本描述或参考图像),三是当前处于创作的哪个阶段 (时间步)。输出则是一个向量 ,指引着画面应该如何演变。
对于简单的 toy(toy 分布,想象一下二维平面上的几个点),一个多层感知器(MLP,Multi-Layer Perceptron)就足够用了——就像用简单的笔触画简单的图形。但当面对真正的照片级图像、高清视频,甚至复杂的蛋白质结构时,MLP 就显得力不从心了。这就像让一个只会画火柴人的画家去绘制蒙娜丽莎——我们需要一个更专业、更强大的架构。
接下来,我们将聚焦于图像(以及扩展到视频)的处理。我们会分两步走:首先学习如何将时间和条件信息”翻译”成神经网络能理解的语言(嵌入技术),然后介绍两位应对高维数据的”高手”——U-Net 和扩散Transformer(DiT)。
6.1.1 条件变量的嵌入
在让神经网络”消化”信息之前,我们首先需要将各种输入转换成它能理解的形式。这就像招待外国客人前,要先把菜单翻译成他们熟悉的语言。
时间的嵌入。 在简单的 toy 模型中,直接把时间值 扔给网络或许还能勉强工作。但在真实场景中,这种”囫囵吞枣”的方式会丢失很多细节。
更优雅的做法是使用傅里叶特征嵌入——这是一种将时间”演奏”成不同频率音符的技术。傅里叶告诉我们,任何复杂的时间模式都可以分解成不同频率的正弦波和余弦波的叠加。想象一下,一首交响乐由许多不同音高的音符组成,时间嵌入也是类似的道理:用不同频率的正弦和余弦函数来表达时间,使网络能够同时捕捉到快速变化和缓慢演变的特征。
具体来说,特征化由下式给出
其中频率 以以下方式设置
这个设计精妙之处在于:频率从低到高呈指数级分布,就像钢琴从低音到高音的排列,高频捕捉快速变化的细节,低频捕捉缓慢变化的趋势。此外,这个嵌入是归一化的——(得益于 ),这确保了不同时间步的表示具有一致的”音量”,不会因为时间值的大小而产生偏差。
类别标签的嵌入。 当 只是一个类别标签时(比如 ImageNet 的 1000 个类别),处理方式相对直接:我们为每个可能的类别学习一个独特的”身份证号”——嵌入向量。比如”猫”这个类别可能对应向量 ,”狗”则对应另一个完全不同的向量。这些嵌入向量不是预先设定好的,而是作为网络参数的一部分,在训练过程中自动学习到的。
文本输入的嵌入。 当条件变成自由形式的文本提示时,事情就变得更有趣了。这就像是要把”画一幅夕阳下的海边小镇”这样的描述转换成一个神经网络能理解的形式。
这个任务通常交给已经预训练好的大型模型来完成,它们就像是精通多国语言的翻译官。其中最著名的就是 CLIP(对比语言-图像预训练)模型。CLIP 的训练方式非常巧妙:让它同时看大量的图像和它们的文字描述,学会在同一个”语义空间”中定位它们——意思相近的图像和文本,它们的嵌入向量在空间中靠得很近。
因此,我们可以直接使用 CLIP 作为”翻译官”:。
但有时候,一个向量难以捕捉丰富文本的全部信息——这就像用一句话描述一幅画,难免有所遗漏。这时,我们可以让文本通过 Transformer 编码器,获得一连串的嵌入向量而非单个向量。此外,将 CLIP 嵌入与其他预训练嵌入(如 T5、UL2 等)组合使用也是很常见的,这就如同邀请多位翻译专家协作,各展所长。
最终,我们假设提示嵌入的形状为
其中 是序列长度, 是每个嵌入向量的维度。
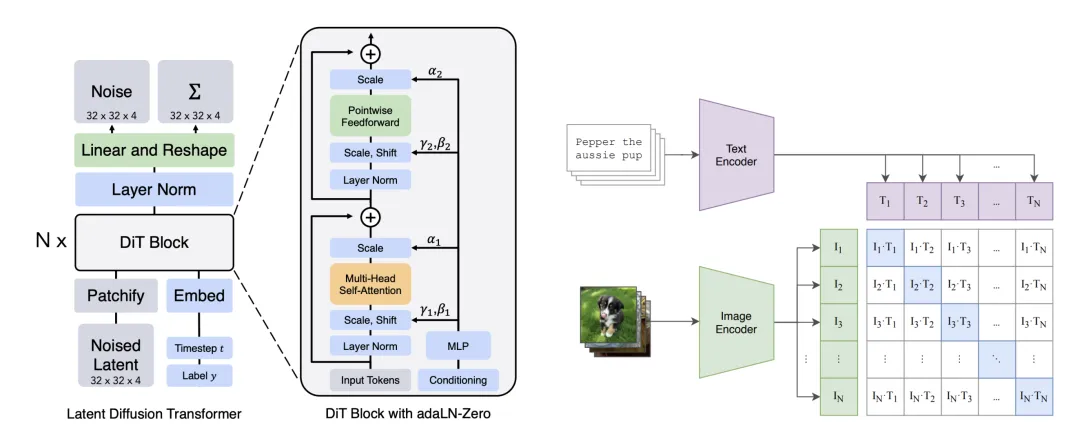
6.1.2 扩散Transformer
让我们先做一个简单的回顾:图像本质上只是一个高维向量 。这里 是通道数(RGB 图像有 个颜色通道), 和 分别是高度和宽度。一张 256×256 的彩色照片,就有 万个数值!
在众多处理图像的架构中,扩散Transformer(DiT)脱颖而出,它使用一种叫做”注意力机制”的技术来理解图像(见 Vaswani et al. (2023),Peebles and Xie (2023),Ma et al. (2024))。如果说传统卷积神经网络是依靠”局部视野”一点点摸索图像,那么注意力机制(attention mechanism)就像是让网络能够同时”看到”整张图,捕捉任意位置之间的关联。
DiT 脱胎于视觉Transformer(ViT,Vision Transformer)。其核心思想很有趣:把图像切分成小块(patches),就像把一幅马赛克拼图拆成一个个小方块,然后把这些小块”翻译”成序列元素,交给 Transformer 处理。
整个过程是怎样的呢?
首先,把图像张量 切分成 patches:
其中 ,, 是每个 patch 的大小(想象一下把 16×16 像素组成一个小方块)。然后,通过线性变换得到 patch 嵌入:
其中 是可学习的权重矩阵。
现在,扩散Transformer需要同时”消化”三类输入:时间嵌入、提示嵌入,以及处理过的图像 patches(参见第 6.1.1 节):
所有这些都被映射到同一个隐藏维度 ,就像把不同货币都兑换成同一种单位。接下来,数据会通过一系列 DiTBlock(如叠积木般堆叠 层),每层都对 patches 之间做自注意力、对齐文本信息、并通过自适应归一化来融入时间信号:
最后,再把这些 patches “拼回”原始图像的形状:
其中 。这个输出 就是我们预测的速度向量 。
备注 29(DiT 模块)
为了完整性,让我们深入了解单个 DiT 层的工作机制。每个 DiT Block 像是一位多面手,同时完成三项关键任务:(i)对图像 patches 的自注意力(让 patches 之间互相”交流”),(ii)对提示的交叉注意力(理解我们要它画什么),以及(iii)通过自适应归一化(AdaLN,Adaptive Layer Normalization)注入时间信息(告诉它现在处于哪个创作阶段)。
首先登场的是缩放点积注意力(scaled dot-product attention)——这是 Transformer 的核心运算。想象一个图书馆管理员,要回答”哪些书与’人工智能’相关”这个问题。管理员需要将”人工智能”转换成查询(Query),然后在所有书籍的键(Key)中搜索匹配,最后返回相关书籍的内容(Value)。在数学上:
给定查询 、键 和值 ,
softmax 在这里起到”软性检索”的作用,将相似度分数转化为概率分布。
多头注意力(multi-head attention)则更进一步——它不是让一个”管理员”完成全部工作,而是同时雇用 个”管理员”(头),每个专注于不同的方面,然后将他们的意见合并。比如第一个头关注颜色,第二个头关注形状,第三个头关注纹理……最后汇总所有人的智慧:
其中源序列 要么是 (自注意力(self-attention),自己问自己),要么是 (交叉注意力(cross-attention),问外部信息)。
连接所有头的输出:
自适应归一化(AdaLN,Adaptive Layer Normalization) 则是一种巧妙的时间调节技术。时间嵌入 首先通过一个小网络 转换为两套参数:
然后用它们来”调制”归一化后的激活:
这就像是根据时间步动态调整神经网络的”音量”和”偏置”,让不同阶段有不同的反应模式。
综合起来,一个完整的 DiT Block 就像一条精密的生产线:
每一行都包含残差连接(residual connection,直连通路),确保信息流顺畅。最终输出的 将流向下一层,成为 。
6.1.3 U-Net
如果说 DiT 是一位擅长处理序列和全局关系的”翻译官”,那么 U-Net 就是一位专注于图像局部细节的”画家”。
U-Net [38] 最初是为医学图像分割设计的——想象一下要从显微镜图像中精准勾勒出细胞轮廓。它的独特之处在于:输入和输出都是图像的形状(只是通道数可能不同)。这使其天然适合参数化向量场 ——因为无论条件如何变化,图像进来,图像出去,非常直观。
U-Net 的结构正如其名字所暗示的——呈现一个优雅的”U”形。它由三部分组成:编码器(Encoder)负责”观察”和”压缩”信息,解码器(Decoder)负责”重建”和”还原”细节,中间还有一个”中转站”——midcoder(我们自创的术语),负责对最浓缩的表示进行进一步处理。
让我们通过一个具体例子,走一遍图像在 U-Net 中的”蜕变”之旅。
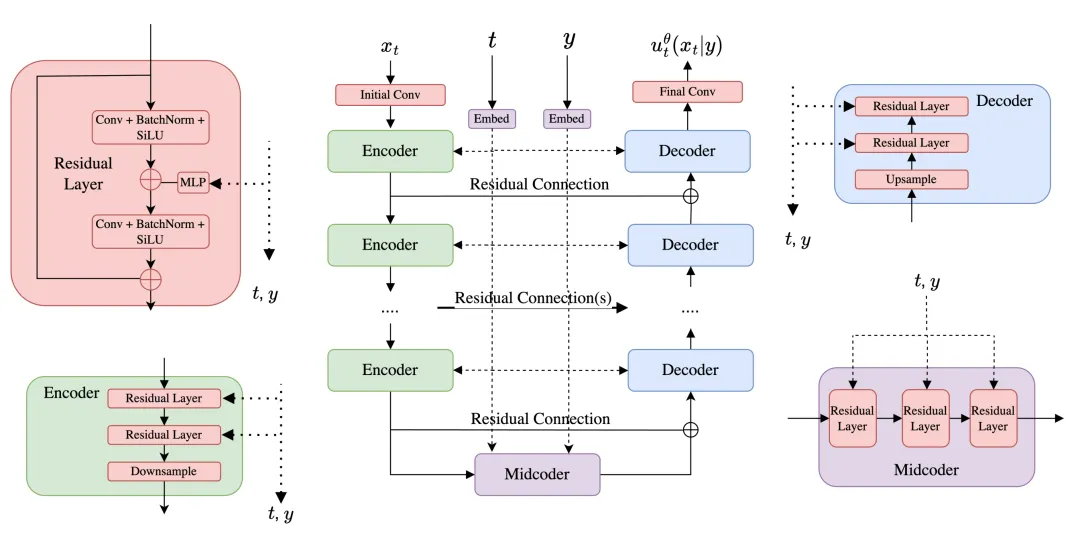
假设我们有一张 的 RGB 图像 ,它在 U-Net 中的旅程如下:
注意这个过程中的一个有趣现象:图像越来越小(从 到 ),但通道数急剧增加(从 3 增加到 512)。这就像把一本厚书压缩成一份详细的摘要——厚度减少,但核心信息反而更集中了。
编码器和解码器都由一系列卷积层堆叠而成(层间穿插着激活函数和池化操作)。有两个实现细节值得注意:输入图像通常先经过一个”预编码块”来提升通道数,然后再送入编码器主体;编码器和解码器之间还有直连的残差连接,如同高速公路般让信息绕过层层变换直接传递。
从高层视角看,大多数 U-Net 都遵循这个”压缩-中转-重建”的三段式结构。当然,实践中的实现各有变体——比如在编码器和解码器中引入注意力层。我们上面展示的是一个纯卷积版本。而 U-Net 得名于其编码器和解码器串联后形成的独特”U”形轮廓(参见图 15)。
备注(Midcoder,中间编码器)
“Midcoder” 这个术语并非标准叫法,这里是我们为了与编码器(Encoder)和解码器(Decoder)形成对应而自创的名称。它指的是 U-Net 这座”U”形桥梁的最底部——信息压缩到极致后的”瓶颈”地带。在这里,图像表示被压缩成最精华的形式,等待解码器重新绽放。
6.2 在潜在空间中工作:(变分)自编码器
前文中,我们一直在数据的”原始空间”中运作。但当面对越来越高清的图像时,这种方式的弊端迅速显现——就像是要在无限大的画布上直接作画,既浪费空间又消耗精力。
举个具体的数字:一幅 的 RGB 图像包含多少个数值?答案是惊人的 万!而视频的维度更是这个数字乘以帧数——简直是爆炸式的增长。相比之下,图像分类任务只需要输出几个类别概率,网络可以”收窄”处理;但我们的流模型要求输出与输入同样大小的向量——这在高清图像上是灾难性的。
这就引出了一个关键问题:我们如何在合理的内存和计算预算内驾驭高维图像?
答案藏在一个优雅的思想中:压缩。真实世界的数据往往并非任意分布于高维空间,而是沿着某种低维流形”安营扎寨”——这就好像地球表面是三维的,但我们只需要经纬度两个坐标就能定位任意地点,因为地球表面是二维流形。图像数据是否也有类似的结构?
6.2.1 标准自编码器
这就把我们引向了自编码器——一种优雅的”压缩-还原”架构。自编码器由两个核心部件组成:编码器 和解码器。编码器像是 Translator A,把图像从庞大的原始空间压缩到一个更紧凑的潜在空间;解码器则像 Translator B,负责把潜在表示还原回原始空间。
用数学语言描述:编码器 将 映射到 ,解码器 做相反的事情。这里的维度 通常远小于 。举例来说,对于 万维的图像,压缩到 万维——整整压缩了 250 倍!
我们希望编码器和解码器配合默契,让重建结果尽可能接近原图。因此,自编码器使用重建损失来训练:
这个损失衡量的是:原图与”编码后再解码”的结果之间有多大差距。
但这里有个陷阱。 重建损失小只能说明自编码器学会了”复制”和”还原”,却无法保证它在潜在空间中学习到了一个”好”的分布。打个比方:想象一个死记硬背的学生,他能把课本上的习题背得滚瓜烂熟,却无法应对变体题目。
具体来说,我们希望在潜在空间中训练生成模型,让 的生成模型能通过”在潜在空间生成 → 解码”的方式工作。但标准的自编码器对潜在分布 几乎没有任何控制——它可能是一个乱七八糟的分布,也可能是一个结构良好的分布,我们无从得知。这就像开盲盒——结果完全不可控。
因此,问题是:我们如何引导潜在分布变得更”乖顺”、更易于学习?这促使我们走向一个更通用的概率框架——变分自编码器。
6.2.2 变分自编码器
变分自编码器(VAE,Variational Autoencoder)的核心思想是:不再让编码器输出确定的向量,而是让它输出一个概率分布——对于每个输入,它不再说”这个图像的潜在代码是 0.5、0.3、-0.8…”,而是说”这个图像的潜在代码服从均值 0.5、方差 0.2 的高斯分布”。
具体来说,我们用 代替原来的确定性编码器,用 代替确定性解码器。最常见的选择是让它们都服从高斯分布:
其中 、 是编码器输出的均值和方差,、 是解码器输出的均值和方差。当方差都为 0 时,VAE 就退化成了标准自编码器。
现在,”编码”变成了从分布中采样:从 中抽取一个 ,然后从 中抽取重建的 。这引入了一种天然的随机性,让模型学会”考虑多种可能性”。
VAE 的重建损失现在变成了:
这个公式问的是:如果编码后再解码,我们能重新得到原始 的可能性有多大?与标准 AE 不同的是,这里我们考虑了所有可能的编码路径(因为每次采样可能得到不同的 )。
对于高斯分布的具体形式,这个损失展开为:
第二项是对方差的惩罚——方差太大意味着模型”不确定”自己的重建,太小又会让模型”过度自信”。实践中,许多实现会将方差固定为常数,从而简化计算。
现在让我们重新思考我们的目标:不仅要重建得好,还要让潜在空间”结构清晰”、易于学习。
打个比方:如果说自编码器是在教学生把图像”压缩成笔记再还原”,那 VAE 还要额外要求——这些笔记必须用一种”标准格式”书写,让未来的”阅卷老师”(生成模型)能轻松理解。
VAE 的做法是:直接在潜在变量 上设定一个先验分布,作为”标准格式”的定义。我们选择各向同性高斯分布(isotropic Gaussian distribution) 作为这个标准格式——因为高斯分布数学性质优良,易于操作和采样。
然后,我们通过额外的损失项强制编码器输出的分布接近这个先验分布:
其中 是 KL 散度(Kullback-Leibler divergence)——衡量两个概率分布”差异有多大”的标准工具。我们稍后会在备注 30 中详细介绍它。
直观上理解,这个损失在说:无论输入是什么图像,编码器都应该输出”像标准高斯分布”的样子。当所有图像的编码都乖乖符合标准格式时,潜在空间的分布自然就是良性的、易于学习的了。
备注 30(KL 散度背景,Kullback-Leibler divergence)
KL 散度(Kullback-Leibler 散度)是信息论中衡量两个概率分布差异的基石概念。对于两个概率密度 和 ,KL 散度定义为
粗略地理解,KL 散度衡量的是:如果我们用分布 来编码来自分布 的样本,需要多少额外的”信息损耗”。它有两个重要的性质:
第一个性质说:KL 散度永远不会为负,最小就是 0。第二个性质说:只有当两个分布完全相同时,KL 散度才为零。这就像温度——零度并不意味着没有温度,只是表示恰好处于冰点。
现在,我们可以把这两部分组合起来,形成 VAE 的完整训练目标:
第一个加数确保”编码-解码”后的重建质量,第二个加数确保潜在分布符合标准格式。参数 是两者的”调解人”—— 越大,潜在分布越紧凑; 越小,重建质量越优先。
对于高斯这个具体的情况,我们可以进一步推导出 KL 散度的闭式解:
例 31(各向同性高斯之间的 KL 散度)
设 和 是两个高斯分布(Gaussian distribution)。那么
这个公式非常直观:如果均值和方差完全一致,KL 散度为 0。均值偏差越大,KL 散度越大;方差偏离越大,KL 散度也越大。特别地,当 时,KL 散度最小化当且仅当 的均值为 0、方差为 1。
当编码器是高斯形式时,先验损失有更简洁的形式:
这个损失的含义一目了然:均值不能离 0 太远(否则会受到 项的惩罚),方差也不能偏离 1 太远(否则会受到 项的惩罚)。
综合起来,VAE 的总损失包含四项:
第一项是重建误差,第二项是解码器的不确定性(方差越大,惩罚越轻),第三和第四项则强制潜在空间符合标准高斯分布。
训练 VAE:重参数化技巧(reparameterization trick)。 还有一个技术细节需要解决:损失中的期望依赖于 ,而 本身包含我们要优化的参数 。在深度学习中,我们希望梯度能流过 ,但采样操作()是随机的,没有梯度。
解决方案是重参数化技巧——把随机性”外包”出去。对于 ,我们不直接从它采样,而是:
关键洞察:现在随机性只来自 ,而 的分布(标准高斯)与 完全无关!这样, 的表达式对 就是可导的了。
重参数化后的损失:
此时随机性完全来自 ,我们可以愉快地用标准梯度下降来训练 VAE 了。
实践备注:来自真实战场的经验。 纸上得来终觉浅,让我们看看实际操作中的权衡与技巧:
-
的选择(以及 KL 预热)。 就像是”压缩率”旋钮——调得太高,潜在空间被压得太紧,重建质量下降;调得太低,潜在空间变得散漫,生成模型难以学习。极端情况下, 太大可能导致”后验崩溃(posterior collapse)”——编码器彻底罢工,对任何输入都输出标准高斯分布。常见的稳定化技巧是”KL 预热(KL warmup)”:训练初期让 从 0 慢慢增长到目标值,给网络一个适应期。现代自编码器的 通常很小(),保持着精细的平衡。
-
解码器方差的处理。 让解码器同时学习均值和方差在数值上可能不稳定,容易”跑偏”。实践中很多实现将解码器方差固定为常数 ,这使得重建项简化为标准的均方误差形式。
-
超越像素级 MSE 的重建损失。 像素级的均方误差会产生过于”模糊”的重建——就像过度压缩的 JPEG 图片。实践中常添加感知损失(perceptual loss):用预训练网络(如 VGG)的特征空间来衡量重建质量,让结果更清晰、语义更保真。
-
对抗性训练(VAE-GAN)。 有时候,重建指标再高,人眼看起来还是差点意思。这时可以引入一个判别器(VAE-GAN 风格,对抗性训练 adversarial training),让生成器和解码器像在玩猫鼠游戏,最终解码器能骗过判别器,产生更逼真的图像。当然,这会引入额外的训练复杂度。
备注 32(在潜在空间中工作)
一旦我们有了训练好的自编码器,就可以在潜在空间中开展生成模型的训练了。流程很简单:训练时从 采样,推理时在潜在空间中运行扩散/流模型生成 ,最后用解码器 还原为图像(注意:推理时通常取均值而非采样,以避免噪声带来的伪影)。
形象地说,一个训练良好的自编码器就像一位技艺高超的策展人:它从海量图像中筛选出核心要素,过滤掉无关的噪声和琐碎的细节,让后续的生成模型能专注于真正重要的特征。正因如此,当今几乎所有最先进的图像和视频生成模型都采用”潜在扩散(latent diffusion)”范式——先压缩、再在压缩空间中进行扩散/流的生成(见 Rombach et al. (2022),Vahdat et al. (2021))。
值得强调的是:这条流水线实际上是两步走——首先训练自编码器(学会压缩和重建),然后再训练扩散模型(学会在潜在空间中生成)。两者的质量缺一不可:自编码器决定了生成模型能看到多少有效信息,以及最终输出的图像有多”美”。
我们在第 D 节中提供关于 VAE 的更多讨论。
6.3 案例研究:Stable Diffusion 3 和 Meta Movie Gen
理论终究要落地生根。让我们把目光转向两个真实的大规模生成系统——它们就像是本教程讲述的各种技术的”集大成者”,同时也展示了如何针对实际问题进行灵活调整。
6.3.1 Stable Diffusion 3
Stable Diffusion 是一个家族,可以说是”让 AI 画图”这件事走入大众视野的先驱之一。这些模型最早证明了”先压缩到潜在空间,再在压缩空间中进行扩散”这条路的可行性。
Stable Diffusion 3 则更上一层楼:它直接采用了我们这篇教程中讲解的条件流匹配目标(参见算法 4),并在此基础上做了大量工程创新。
最大的亮点之一是文本条件的处理。之前的模型可能只用一种文本嵌入,但 Stable Diffusion 3 采用了”三管齐下”的策略:同时使用 CLIP 嵌入(捕捉文本的整体语义)、Google T5 编码器的输出(提供更细粒度的上下文信息),就像同时请了多位翻译家协作,每个人各有所长。
为了让模型更好地理解文本,他们还提出了多模态 DiT(MM-DiT)架构——让 DiT 不仅关注图像 patches,还同时关注文本嵌入,实现更深层次的跨模态理解(参见图 16)。最终模型参数量达到 80 亿!采样时使用 50 步,配合 Euler 模拟器(Euler simulator)和无分类器引导(classifier-free guidance,引导权重 2.0-5.0)。

6.3.2 Meta Movie Gen Video
如果说 Stable Diffusion 3 是画单幅图片的高手,那 Meta 的 Movie Gen Video 就是编织动态画卷的大师。
视频与图像的本质区别在于:时间。视频数据可以表示为 ,其中多出来的 就是帧数(frame)。一段 30fps 的 10 秒视频就包含 300 帧图像!处理视频的关键挑战,就是如何驾驭这额外的时间维度。
Movie Gen Video 同样采用条件流匹配目标(直线调度器 ,),并且同样在预训练自编码器的潜在空间中工作。对于视频而言,高效压缩的自编码器甚至比图像更重要——因为视频的数据量是图像的数百倍,稍有不慎就会爆掉内存。
针对时间维度,Movie Gen Video 引入了时间自编码器(TAE,Temporal Autoencoder):将原始视频 压缩到 ,其中时间维度被压缩了 8 倍(),空间也被相应压缩。对于超长视频,他们还提出了”时间平铺”策略——把视频切成小段分别编码,再拼接成连贯的潜在表示。
模型主干是 DiT 类的 Transformer,但它同时在时间和空间两个维度上进行 patchify 和自注意力(self-attention),实现对时空双重维度的建模。文本条件方面也是”三路并进”:UL2 嵌入(细粒度推理)、ByT5 嵌入(字符级别的精确控制,比如用户要求视频中出现特定文字)、以及 MetaCLIP 嵌入。
最终,Movie Gen Video 的最大模型参数量达到惊人的 300 亿——是 Stable Diffusion 3 的近四倍!
专业名词表
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
参考文献
-
Ma et al. “Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers”. arXiv:2401.08740 (2024). -
Peebles and Xie. “Scalable Diffusion Models with Transformers”. arXiv:2212.09748 (2023). -
Rombach et al. “High-Resolution Image Synthesis with Latent Diffusion Models”. arXiv:2112.10752 (2022). -
Vahdat, Kreis, Kautz. “Score-based generative modeling in latent space”. NeurIPS (2021). -
Vaswani et al. “Attention Is All You Need”. arXiv:1706.03762 (2023).